Evaluation Pipeline
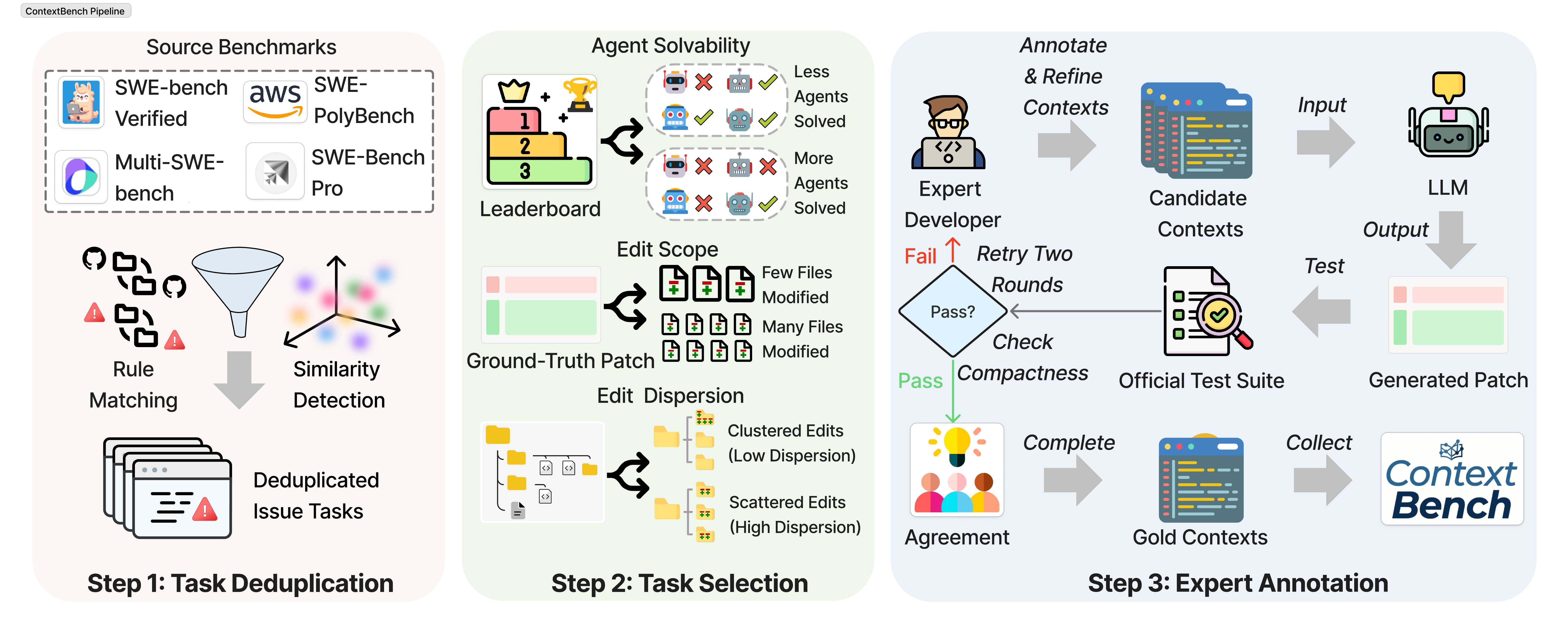
Download full pipeline diagram (PDF)
Overview
ContextBench evaluates agents through a systematic pipeline that compares predicted context (from agent trajectories) against gold annotations (human-verified context) at multiple granularities.
Pipeline Steps
1. Trajectory Extraction
Extract file views and spans from agent trajectories:
Parse trajectory format (
.traj.json,.checkpoints.jsonl, etc.)Identify file access commands (
cat,view,grep, etc.)Extract line ranges and byte spans for each viewed file
Track per-step context evolution
2. Repository Checkout
Clone and checkout the target repository:
Use cached clones when available
Checkout the specific commit/version for the task
Verify repository state matches gold annotations
3. Symbol Extraction
Use tree-sitter to extract code symbols:
Parse files to build abstract syntax trees (AST)
Identify definitions: classes, functions, methods
Map byte spans to symbol boundaries
Handle 8 programming languages: Python, Java, JavaScript, TypeScript, Go, Rust, C, C++
4. Gold Context Loading
Load human-annotated gold context:
File-level: Set of relevant file paths
Symbol-level: Set of relevant class/function definitions
Span-level: Byte intervals of relevant code regions
EditLoc-level: Locations where edits were made
5. Metric Computation
Compute metrics at multiple granularities:
Set-based metrics (File, Symbol):
Interval-based metrics (Span):
Trajectory metrics:
AUC-Coverage: Area under the per-step coverage curve (measures efficiency)
Redundancy: Fraction of context re-examined across steps
6. Result Aggregation
Output comprehensive evaluation:
Per-instance metrics (JSON Lines format)
Aggregated statistics (macro/micro averages)
Trajectory visualization data
Granularity Levels
File-Level
Evaluates which files were retrieved:
Gold: Set of file paths that contain relevant context
Pred: Set of files the agent viewed
Use case: Coarse-grained context retrieval
Symbol-Level
Evaluates which code symbols (functions, classes) were identified:
Gold: Set of (file, symbol_name) tuples with relevant definitions
Pred: Symbols covered by viewed spans
Use case: Fine-grained context understanding
Span-Level
Evaluates exact byte ranges of viewed code:
Gold: Union of byte intervals containing relevant code
Pred: Union of byte intervals the agent examined
Use case: Most precise retrieval measurement
EditLoc-Level
Evaluates edit location prediction:
Gold: Lines where the ground-truth patch made changes
Pred: Lines the agent identified for editing
Use case: Measures localization accuracy
Supported Formats
ContextBench automatically detects and parses multiple trajectory formats:
MiniSWE-agent:
.traj.jsonfilesSWE-agent:
.checkpoints.jsonlfilesAgentless: Custom JSON format
OpenHands: Trajectory logs
Prometheus: Agent-specific format
See Agent Trajectory Extractors for details on each format.
Next Steps
Understand the Metrics in detail
Learn about Agent Trajectory Extractors trajectory formats
See Evaluation for advanced usage